This post was originally written for Minjar Blog and it was first published here.
One of our customers was running a Riak cluster on Amazon EC2 and we had to design a backup strategy for this cluster. In order to come up with a backup strategy, one must first understand how Riak works, the kind of problems it solves, how things like consistency are handled.
So What Is Riak
Riak is a scalable, highly available, distributed key-value store. Like Cassandra, Riak was modelled on Amazon’s description of Dynamo with extra functionality like mapreduce, indexes and full-text search. A comparison of Riak with other NoSQL databases is out of the scope of this article, but checkout this great summary by Kristof
How Does a Riak Cluster Work?
Data in a Riak cluster is distributed across nodes using consistent hashing. Riak’s clusters are masterless. Each node in the cluster has same data, containing a complete, independent copy of Riak package. This design ensures fault-tolerance and scalability. Consistent hashing ensures data is distributed across all nodes in the cluster evenly.
How Does Replication Work?
Riak allows you to tune the replication number, which is n value in Riak speak. The default value is ‘3’, which means that each object is replicated 3 times. At the time of this writing, Basho says that it is almost 100% sure that this piece of replicated data is in three different physical nodes and they are working towards guaranteeing that it will be so in future.
Riak’s take on CAP (as an aside, you must read this Plain English Introduction To CAP theorem) is they let you tune N - Number of replicated nodes per bucket, R - number of nodes required for a read and W - number of nodes required for a successful write. Riak requires a minimum of 4 nodes to set up but ideally, you must be running at least 5 node cluster. Here are details of why. To summarize:
- If you have a 3 node cluster with N value as 3, When a node goes down, your cluster wants to replicate to 3 nodes, but you only have 2 and there is a risk of performance degradation and data loss
- If you have a 4 node cluster with N value as 3, The reads use a quorum of 2 and writes use a quorum of 2. When a node goes down, 75 to 100 % of your nodes need to respond.
- The best configuration is N value + 2 nodes. A 5 node cluster with N value 3, R value 2, W value 2 is best for scalability, high availability and fault-tolerance.
Eventual Consistency and How Riak deals with Node Failures
So how is ‘eventual consistency’ achieved in our 5 node cluster? When data is written to this cluster with write quorum of 2, the data will still be sent to all three replicas (n value is 3). It doesn’t matter if one of the primary nodes is down. When the node comes back, Read Repair kicks in and makes sure that the data becomes eventually consistence.
Implementing Riak on AWS and Backing up Riak
So with all the knowledge about we have about Riak so far, the implementation should look like this on AWS EC2.
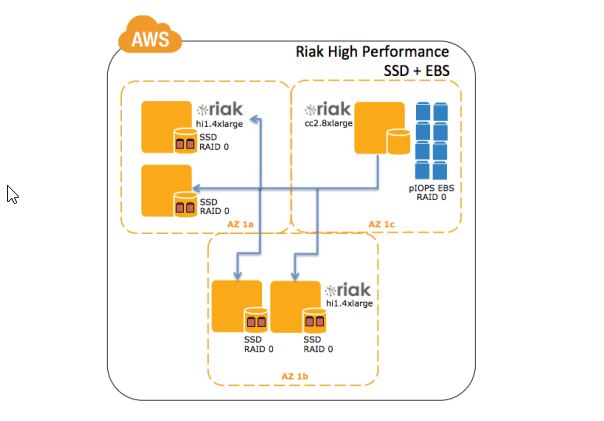
Source: Running Riak On AWS - White Paper
Now to the backup part. There is a riak-admin backup command which can be used to take backup but this has been deprecated and Basho suggests taking backups at file system level. There are multiple backends available in Riak. If you use LevelDB as your backend, you need to shut down the node, take a filesystem level backup and then start the node. If you are using Bitcask and if you are on AWS EC2 it becomes easier. You don’t need to bring the node offline for bitcask and a simple EBS snapshot would do.
You can either use tar, rsync or filesystem level snapshots. If you go with tar and/or rsync - below are the directories you should be backing up:
- Bitcask data: ./data/bitcask
- LevelDB data: ./data/leveldb
- Ring data: ./data/riak/ring
- Configuration: ./etc
The path of these folders varies Linux distro to distro. here is the complete list. So for our 5 node cluster running on AWS EC2 with Bitcask backend, you can just schedule periodic snapshot jobs on each node and you will be safe. A slight inconsistency in data during backups is allowed due to the eventual consistency of Riak. When we restore from that backup, Read Repair feature will kick in and make it eventually consistent.
Restoring From A Backup
Assuming a node fails. Below are steps for recovering:
- Install Riak on a new node.
- Restore from failed node’s backup/snapshot
- Start the node and verify if
Riak ping,riak-adminstatusetc works - If you are restoring this node with the same name, then you first need to mark the original node as down.
riak-admin down failednode - Join the new node to cluster
riak-admin cluster join newnode - Replace original with new
riak-admin cluster force-replace failednode newnode - Plan changes:
riak-admin cluster plan - Commit changes
riak-admin cluster commit
Hope this was helpful!
References
- Eventual Consistency
- Replication
- Failure And Recovery
- Backing up Riak
- Running Riak on AWS
- Why your Riak cluster must be atleast 5 nodes
- Repair and Recovery